
Stufe 1: Verstehen – Schritt für Schritt zur Generative AI Applikation
ℹ️ Dies ist der erste Artikel aus einer in den kommenden Monaten entstehenden Serie. Er stellt ein allgemeines Playbook für die Entwicklung von Generative AI Anwendungen vor. In Folgeartikeln werden die einzelnen Stufen jeweils detailliert behandelt. Den Einführungsartikel findet man hier.
Im ersten Artikel dieser Serie habe ich ein Playbook für die Entwicklung von LLM-Anwendungen vorgestellt, welches sechs Stufen beschreibt. In diesem Artikel geht es nun ans Eingemachte: Wir zoomen in Stufe 1 – Verstehen – hinein und ich beschreibe im Detail, was ich damit meine und wie man diesen Schritt praktisch angeht. Nicht zufällig steht 'Verstehen' im Pyramidenmodell ganz unten: Es ist das Fundament, auf dem alle weiteren Stufen ruhen. Wer hier wackelt, kann oben nichts Stabiles bauen.
Worum geht es? Bevor wir Software bauen, bevor wir über Tech Stacks oder Frameworks diskutieren, müssen wir eine ganz grundlegende Frage beantworten: Kann KI unser Problem überhaupt lösen und wie sieht eine gute Lösung aus? Das klingt banal, wird aber erschreckend oft übersprungen. Ich habe in den vergangenen Jahren zu viele Teams erlebt, die irgendwie mit LLMs experimentieren, ohne klar definiert zu haben, was eigentlich rauskommen soll. Die Folge kennt Ihr: Prompts werden umgeschrieben und umgeschrieben und irgendwann wird die Initiative leise beerdigt, weil sie hinter den nebulösen Erwartungen zurückbleibt.
Damit Euch das nicht passiert, gehen wir das Thema hier einmal Schritt für Schritt durch. Wie immer gilt: Ich beschreibe, was in meiner praktischen Arbeit funktioniert hat. Wenn Ihr es anders seht oder ergänzen wollt – schreibt mir gerne an jan@produktkraft.com. Diese Serie lebt vom Austausch.

Vorweg einmal eine Erdung: Wie können Beispiele für einfache KI-Anwendungen aussehen, für die sich dieses Playbook eignet: Ich meine damit Produkte wie einen Chatbot, der Psychotherapeuten bei der Arbeit durch Supervision unterstützt (und ja, genau so etwas bootstrappe ich gerade selbst – schaut mal auf ganzheit-app.com vorbei, falls Euch das interessiert), ein Data-Warehouse-Reporting-Tool, welches SQL generiert und Daten interpretiert, oder einen Sales-Helfer, der E-Mails basierend auf CRM-Daten vorformuliert. Produkte also, bei denen ein Large Language Model den Kern der Wertschöpfung bildet und in denen es darum geht, einen Input in einen nützlichen Output zu transformieren.
Warum jetzt der richtige Zeitpunkt zum Experimentieren ist
Im Übersichtsartikel habe ich geschrieben, dass es in der aktuellen Phase okay ist, einfach loszulegen und KI einzusetzen – auch wenn der idealistische Produktmanagement-Theoretiker in mir am liebsten erst die Produktvision und den Opportunity Solution Tree sehen würde. Diesen Gedanken möchte ich hier vertiefen, denn er ist für die Haltung in Stufe 1 entscheidend.
Die Möglichkeiten von Generative AI verändern sich in einer Geschwindigkeit, die ich in meinen zwölf Jahren digitaler Produktarbeit so noch nicht erlebt habe. Was vor sechs Monaten nicht funktioniert hat, funktioniert heute vielleicht hervorragend. Und was aktuell State of the Art ist, wird in einem halben Jahr möglicherweise von einem neuen Modell in den Schatten gestellt. Wer sich in dieser Situation ein festes Bild davon macht, was KI kann und was nicht, der irrt sich möglicherweise schon beim nächsten Model-Release.
Ein praktisches Beispiel: Als Anthropic den Sprung auf Claude Opus 4.5 vollzogen hat, hat sich für die Welt des Vibe Codings fundamental verändert. Auf einmal war es möglich, in komplexen Codebases produktiv mit KI zu arbeiten – etwas, das mit den Vorgängermodellen schlicht nicht zuverlässig funktioniert hat. Plötzlich ist Vibe-Coding nicht mehr nur für MVPs und Protoypen, sondern macht auch ernste Engineering-Arbeit schneller (mit allen Nachteilen, die das mit sich bringt: 1, 2). Hätte man zu dem Zeitpunkt ein "Ich weiß schon, was geht und was nicht"-Mindset gehabt, wäre ich nie auf die Idee gekommen, das überhaupt auszuprobieren. Und genau das ist der Punkt: In einer Technologie, die sich so rasant entwickelt, ist Experimentieren keine Spielerei, sondern die einzige verantwortungsvolle Haltung.
Damit das Experimentieren aber kein zielloses Herumprobieren wird, brauchen wir eine Methode. Und die beginnt mit einer überraschend einfachen Frage.

Wie sehen mein idealer Input und mein idealer Output aus?
Wenn ich eine einfache AI Anwendung entwickeln will, dann ist der allererste Schritt nicht ein Architekturdiagramm und auch kein Prompt. Der allererste Schritt ist, mir über zwei Dinge klar zu werden: Was geht rein und was soll rauskommen?
Das klingt fast zu simpel, ist aber der Kern von allem, was danach kommt. Large Language Models sind, bei aller Faszination, statistische Modelle, die auf einen Input einen Output generieren. Um bewerten zu können, ob dieser Output gut ist, muss ich vorher wissen, wie gut aussieht. Und um den richtigen Input zu liefern, muss ich verstehen, welche Informationen das Modell braucht.
Lasst mich das an den drei Beispielen durchspielen.
Beim Supervision-Chatbot für Therapeuten muss ich verstehen, welche Fragen Therapeuten in der Supervision typischerweise stellen. Geht es um Fallkonzeptionen? Um den Umgang mit schwierigen Therapiesituationen? Um die Einordnung von Symptomen? Und dann muss ich wissen, wie eine gute Antwort aussieht – fachlich korrekt, differenziert, mit dem richtigen Grad an Vorsicht bei sensiblen Themen.
Beim Data-Warehouse-Reporting-Tool ist die Frage: Welche Fragen stellen meine Business Stakeholder? "Wie hat sich der Umsatz in Q3 im Vergleich zum Vorjahr entwickelt?" zum Beispiel. Und der ideale Output? Ein korrektes SQL-Statement, das die richtigen Tabellen und Joins verwendet, plus eine verständliche Erklärung der Ergebnisse – inklusive der Limitierungen der Daten. Denn ein Data-Warehouse-Tool, das souverän eine Zahl ausspuckt, ohne zu erwähnen, dass die Datenquelle für den Zeitraum unvollständig ist, ist gefährlicher als keins.
Beim Sales-Helfer lautet die Frage: Wie greifen exzellente Salesleute die Kommunikation mit Prospects auf? Welchen Ton treffen sie? Wie personalisieren sie basierend auf CRM-Daten, ohne dass es creepy wirkt? Der ideale Output ist eine vorformulierte E-Mail, die ein guter Salesperson mit minimalen Anpassungen versenden würde.
Ihr merkt: Dieser Schritt hat überhaupt nichts mit Technologie zu tun. Es ist pure Domänenarbeit. Und genau hier liegt ein blinder Fleck, den ich explizit benennen möchte: Um den idealen Output definieren zu können, braucht Ihr Expertise in dem Fachgebiet, für das Ihr die Anwendung baut. Beim Supervision-Tool muss jemand im Team verstehen, was gute Supervision ist. Beim Data-Warehouse-Tool muss jemand SQL können und die Datenstruktur kennen. Beim Sales-Helfer braucht es jemanden, der weiß, wie erstklassige Sales-Kommunikation aussieht.
Ohne diese Expertise lauft Ihr Gefahr, Euch vom eloquenten Output des LLMs blenden zu lassen. Denn eines können diese Modelle ausgesprochen gut: überzeugend klingen, auch wenn sie inhaltlich danebenliegen. Die Fähigkeit, das zu erkennen, kommt nicht aus dem Prompt – sie kommt aus Eurem Wissen über die Domäne.
Deine ersten Evals entstehen fast nebenbei
Die Paare aus Fragestellung und idealer Antwort, die Ihr gerade definiert habt, haben einen Namen: Evals. Das Wort wird Euch in der Generative-AI-Welt immer wieder begegnen und es klingt technischer, als es an dieser Stelle ist. Im Grunde sind Evals einfach Testfälle: "Wenn ich das hier reingebe, sollte ungefähr das hier rauskommen." und für den aktuellen Stand, können die in einem Spreadsheet oder Textdokument leben. Ein Tipp: Fügt einfach eine Zeile für jede Iteration Eures Contexts und Prompts hinzu.
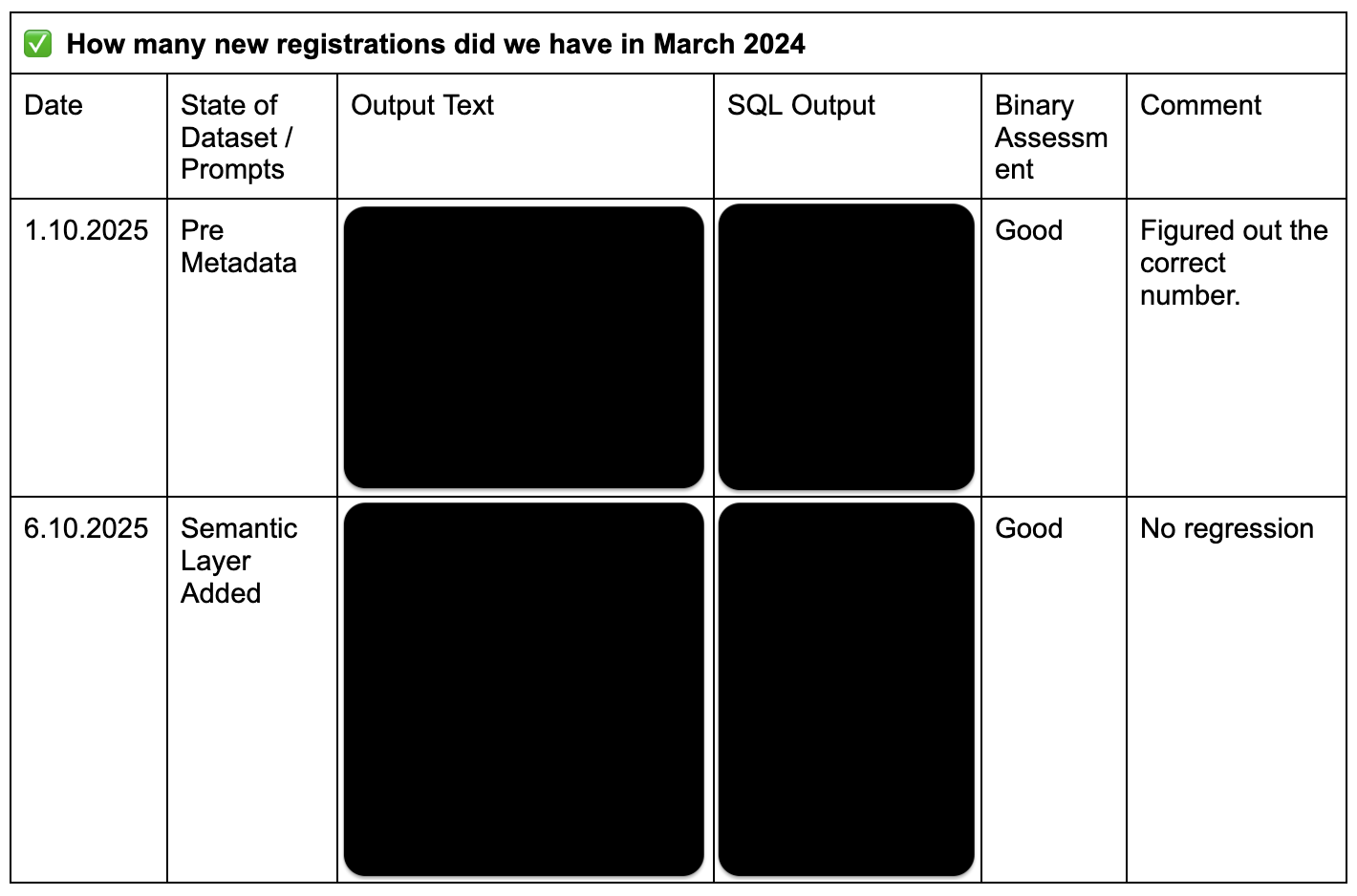
Beispiel für ein hemdsärmeliges Eval Setup im Doc
Denkt an eine Arbeitsprobe im Vorstellungsgespräch. Ihr gebt jemandem eine Aufgabe und habt ein Bild davon, wie eine gute Lösung aussieht. Danach könnt Ihr bewerten, ob die Person – oder in unserem Fall das Modell – den Job kann. Die Analogie zu Test Driven Development liegt ebenfalls nahe: Man definiert erst, wann etwas gut genug ist, bevor man anfängt zu bauen.
Macht Euch an dieser Stelle keinen Kopf darum, wie man Evals systematisch aufsetzt oder automatisiert – das kommt in späteren Artikeln dieser Serie noch ausführlich zur Sprache, insbesondere wenn wir über MVP und Tech Stack in Stufe 2 und über den Full Rollout in Stufe 6 sprechen. Für den Moment reicht dieses intuitive Verständnis vollkommen: Ihr habt definiert, was rein- und was rauskommen soll, und damit habt Ihr Eure ersten Testfälle in der Hand.
Ran an die KI – aber noch ohne Code
Jetzt wird es praktisch. Öffnet einen Chat mit einem KI-Tool Eurer Wahl: ChatGPT, Gemini, Claude – am Anfang empfehle ich, alle einmal auszuprobieren, denn die Modelle unterscheiden sich in ihren Stärken und Schwächen durchaus relevant.
Was tut Ihr? Genau das, was Eure Anwendung später auch tun soll. Gebt dem Modell den Input, den Eure Applikation später haben wird, und verlangt den Output, den Eure Applikation später liefern soll. Konkret: Schreibt in den Chat eine typische Frage, die ein Therapeut, ein Business Stakeholder oder ein Salesperson stellen würde, und schaut, was passiert.
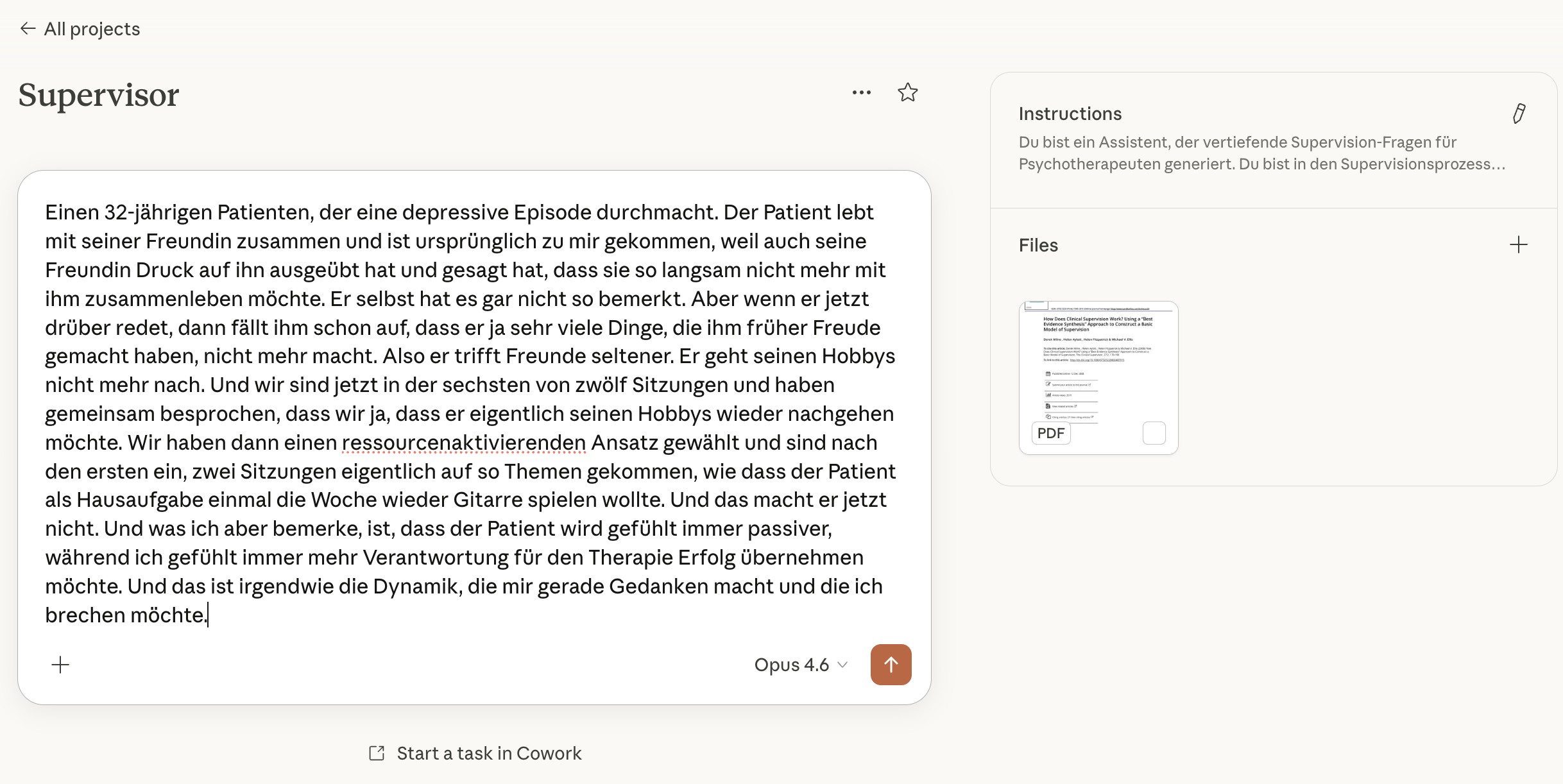
Beispiel eines Claude Projektes mit Angehängten Dokumenten und Instructions
Zwei Dinge sind in dieser Phase besonders wichtig.
Erstens: Arbeitet mit realistischen, aber anonymisierten Daten. Wenn Ihr einen Supervision-Chatbot testet, kippt keine personenbezogenen Patientendaten in den Chat. Beim Sales-Helfer, ändert Namen und Adressdaten in CRM-Exports. Erstellt anonyme, aber realistische Testdaten, die der echten Nutzung so nahe wie möglich kommen. Das ist nicht nur datenschutzrechtlich geboten, sondern gibt Euch auch früh ein Gefühl dafür, welche Art von Daten Eure Anwendung im Alltag verarbeiten muss.
Zweitens: Lasst Euch nicht vom Shiny-Output-Effekt blenden. LLMs produzieren immer Texte, die sich gut lesen und professionell klingen. Die Frage ist aber nicht, ob die Antwort beeindruckend klingt, sondern ob sie Eurem vorher definierten idealen Output entspricht. Prüft hart gegen Eure Evals. Ist das SQL korrekt? Ist die Supervision-Antwort fachlich richtig und angemessen differenziert? Würde ein erfahrener Salesperson die vorformulierte E-Mail so abschicken? Diese Fragen sind die einzigen, die zählen.
Iteriert dann so lange mit dem Prompt und den verschiedenen Modellen, bis der Output dem Ideal nahekommt. Ändert die Formulierung des Prompts. Fügt mehr Kontext hinzu. Gebt dem Modell eine Rolle. Schränkt das Ausgabeformat ein. Probiert dasselbe mit einem anderen Modell. In dieser Phase lernt Ihr enorm viel darüber, was die KI wirklich für Euch tun kann – und was nicht.
Erweitern und ehrlich bleiben
Wenn Eure ersten Input/Output-Paare gut funktionieren, ist es Zeit, den Testumfang zu erweitern. Formuliert weitere Fragen, die in den ersten Evals noch nicht dabei waren. Denkt an Edge Cases: Was passiert, wenn die Frage unklar formuliert ist? Was wenn der Input unvollständig ist? Was wenn jemand etwas fragt, das nichts mit dem eigentlichen Anwendungsfall zu tun hat?
Korrigiert Eure Prompts, bis Ihr mit den Antworten über dieses breitere Set an Fragen zufrieden seid. Das wird einige Runden dauern und das ist normal. Schöner Nebeneffekt: Ihr gewinnt eine gewisse Inuitition für die Jagged Frontier von AI.
Ein Punkt, der in dieser Phase oft übersehen wird: Es reicht nicht, einmal eine gute Antwort zu bekommen. Was Ihr prüfen müsst, ist, ob das LLM das Problem konsistent löst. Stellt dieselbe Frage mehrmals. Variiert die Formulierung leicht. Denn ein Modell, das in einem glücklichen Einzelfall eine brillante Antwort liefert, aber beim nächsten Versuch danebenliegt, ist für eine Produktanwendung nicht brauchbar. Deterministische Software tut bei gleichem Input immer dasselbe – LLMs nicht. Diese Eigenschaft müsst Ihr von Anfang an im Blick haben.
Der erste Check: Kann KI Dein Problem heute lösen?
Wenn Ihr die oben beschriebenen Schritte durchlaufen habt und mit den Ergebnissen zufrieden seid – herzlichen Glückwunsch! Der erste Check ist bestanden: KI kann Euer Problem heute lösen, zumindest prinzipiell. Ihr habt nun eine solide Grundlage, um in Stufe 2 den Bau eines MVP in Angriff zu nehmen.
Aber was, wenn der Check fehlschlägt? Wenn die Antworten trotz aller Prompt-Iterationen nicht gut genug sind? Dann stellt Euch ehrlich die Frage, ob KI für diesen Anwendungsfall zum jetzigen Zeitpunkt der richtige Ansatz ist. Und das ist eine völlig okay Erkenntnis. Besser jetzt als nach drei Monaten Entwicklung.
Allerdings – und das ist mir wichtig – heißt das nicht, dass die Idee tot ist. Erinnert Euch an den Anfang dieses Artikels: Die Möglichkeiten verändern sich rasant. Mein konkreter Tipp: Notiert Euch das Experiment und wiederholt es beim nächsten Release eines Flagship-Modells.
Auch hier ein persönliches Beispiel: Die Supervision mit klinischen Fällen, also genau der Anwendungsfall meines eigenen Produkts, war in den LLMs von vor einem Jahr schlicht nicht gut. Die Antworten waren banal, die Modelle waren overconfident und die fachliche Differenzierung fehlte. Hätten wir zu dem Zeitpunkt aufgegeben, gäbe es die Ganzheit-App heute nicht. Aber mit den aktuellen Modellen funktioniert es. Nicht perfekt, aber gut genug, um weiterzuarbeiten und zu iterieren. Und genau das ist der Geist dieses Playbooks: Wir bauen nicht die perfekte Software, wir bauen Software, die gut genug ist, um am Kontakt mit der Realität besser zu werden.

Wie es weitergeht: Stufe 2 – MVP & Tech Stack
Wenn Stufe 1 grünes Licht gegeben hat, geht es weiter mit der spannenden Frage: Wie bauen wir das eigentlich? In Stufe 2 reden wir darüber, welche technischen Aspekte für das MVP nötig sind, wie wir sicherstellen, dass wir Evals nicht dauerhaft von Hand durchführen müssen, und wie wir die Kosten im Blick behalten – denn ein LLM-basiertes Produkt kann in der Infrastruktur schnell teurer werden als man denkt.