
Stufe 2: MVP & Tech Stack – Schritt für Schritt zur Generative AI Applikation
ℹ️ Dies ist der zweite Detail-Artikel aus einer Serie, in der ich aus Produktmanagement-Perspektive Schritt für Schritt beschreibe, wie eine Generative-AI-Anwendung praktisch zu bauen ist. Den Einführungsartikel mit dem Überblick über alle sechs Stufen findet Ihr hier. Den Artikel zu Stufe 1 – Verstehen findet Ihr hier.
Im letzten Artikel haben wir uns in Ruhe darum gekümmert, zu verstehen, was unsere KI eigentlich tun soll und wie ein guter Output aussieht. Wir haben mit ChatGPT, Claude oder Gemini im Chat herumgespielt, unsere idealen Input/Output-Paare durchiteriert, daraus die ersten Evals abgeleitet und am Ende für uns selbst grünes Licht gegeben: Wir haben ein eigenes Bild einer guten Antwort entwickelt und Ja, eine KI kann unser Problem heute prinzipiell lösen.
Jetzt wird es ernst. Wir verlassen den geschützten Spielplatz der Chat-Interfaces und beginnen, eine echte Applikation zu bauen. In diesem Artikel zoome ich in Stufe 2 – MVP & Tech Stack – hinein und beschreibe, welche technischen Bausteine wirklich nötig sind, um schnell und sinnvoll iterieren zu können. Und mindestens genauso wichtig: welche Bausteine an dieser Stelle noch nicht nötig sind, obwohl viele laute Stimmen aus dem KI-Hype-Cycle Euch davon überzeugen wollen.

Vorweg eine Beruhigung: Auch wenn wir jetzt Code schreiben, gelten weiterhin die ganz normalen MVP-Regeln, die wir alle aus der digitalen Produktarbeit kennen. Good enough to experiment, Lean Startup, Build–Measure–Learn. Unser unmittelbares Ziel ist nicht die Skalierung an tausende NutzerInnen, sondern etwas, das uns ans Lernen bringt. Mit dieser Haltung im Hinterkopf schauen wir uns einmal die vier Themen an, auf die es im Hinblick auf den initialen Tech Stack ankommt.
Prompt Management und Tracing – die wichtigste Investition zu Beginn
Wenn ich an dieser Stelle nur eine einzige Empfehlung weitergeben dürfte, wäre es diese: Setzt von Anfang an ein Tool für Prompt Management und Tracing ein. Ich weiß, das klingt nach Tooling-Overhead in einer Phase, in der man eigentlich nur schnell etwas bauen will. Aber ich versichere Euch, dass dieses kleine Investment seine Zeit wert ist, und zwar aus zwei Gründen.
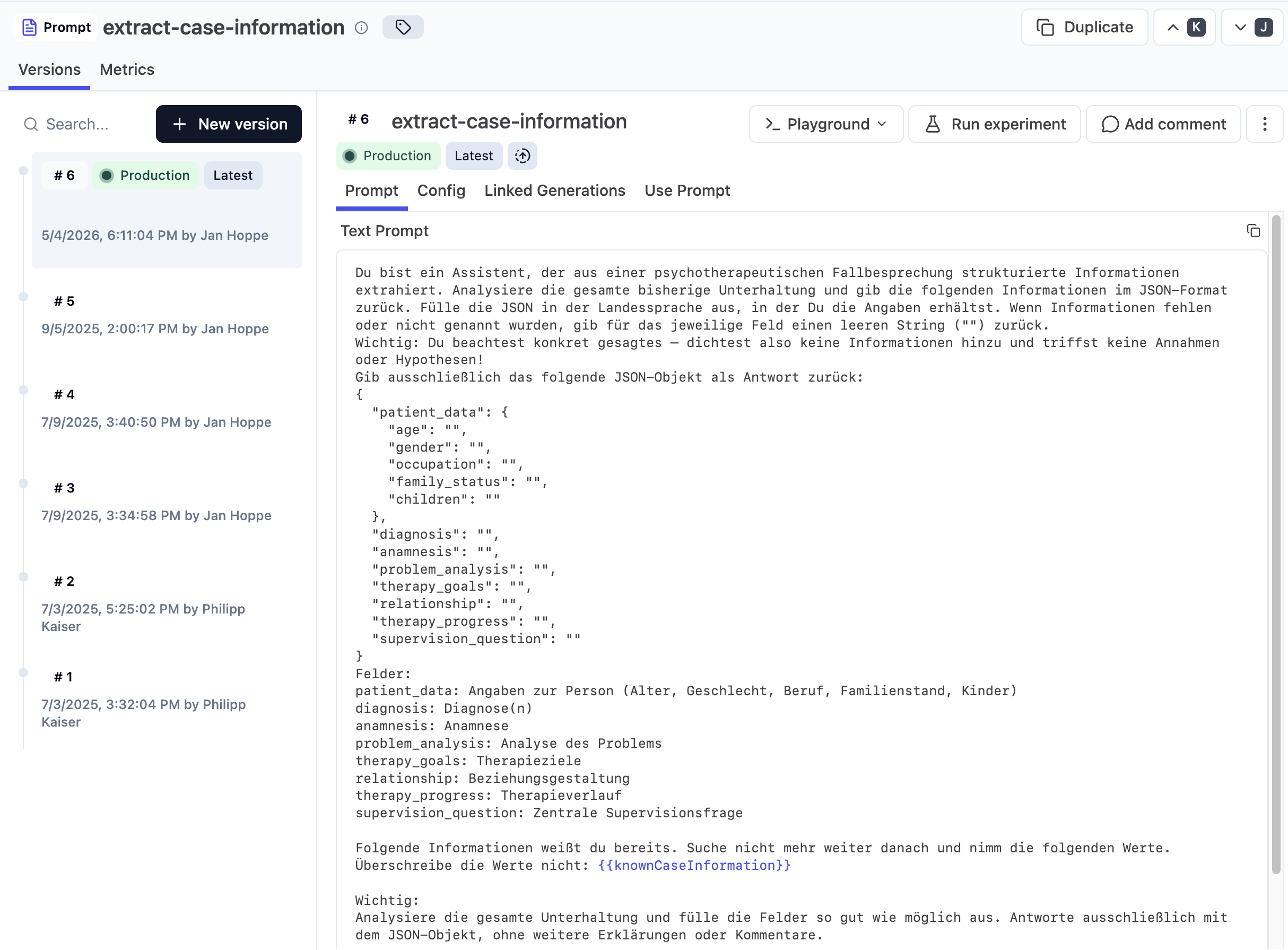
Beispiel für einen versionierten Prompt in LangFuse
Der erste Grund ist banal: Prompts gehören nicht in den Code. Wenn Euer Prompt im Code lebt, dann braucht Ihr für jede kleine Anpassung – und Ihr werdet sehr viele kleine Anpassungen machen – einen Deployment-Zyklus. Das ist langsam, das ist nervig, und vor allem schließt es nicht-technische Teammitglieder aus dem Iterationsprozess aus. Was Ihr stattdessen wollt, ist etwas, das sich anfühlt wie ein CMS für Prompts: eine Oberfläche, in der Ihr Prompts versionieren, ändern und deployen könnt, ohne dass Engineering eingreifen muss. Plötzlich kann jede Produktperson oder jeder Domänenexperte mitarbeiten und in Sekunden eine Idee testen.
Der zweite Grund ist mindestens genauso wichtig: Ihr müsst sehen, was Eure KI tut. In klassischer deterministischer Software wisst Ihr, was passiert, weil Ihr es so programmiert habt. Bei Large Language Models wisst Ihr es nicht – Ihr müsst nachschauen. Konkret heißt das: Ihr braucht eine Liste aller Inputs, die in Eure Anwendung gehen, und aller Outputs, die rauskommen. Das nennt sich Tracing, und es ist die Grundvoraussetzung dafür, überhaupt bewerten zu können, wie gut Eure Antworten sind. Ohne Traces seid Ihr blind. Mit Traces könnt Ihr Schwächen identifizieren, Edge Cases entdecken und Eure Evals systematisch erweitern.
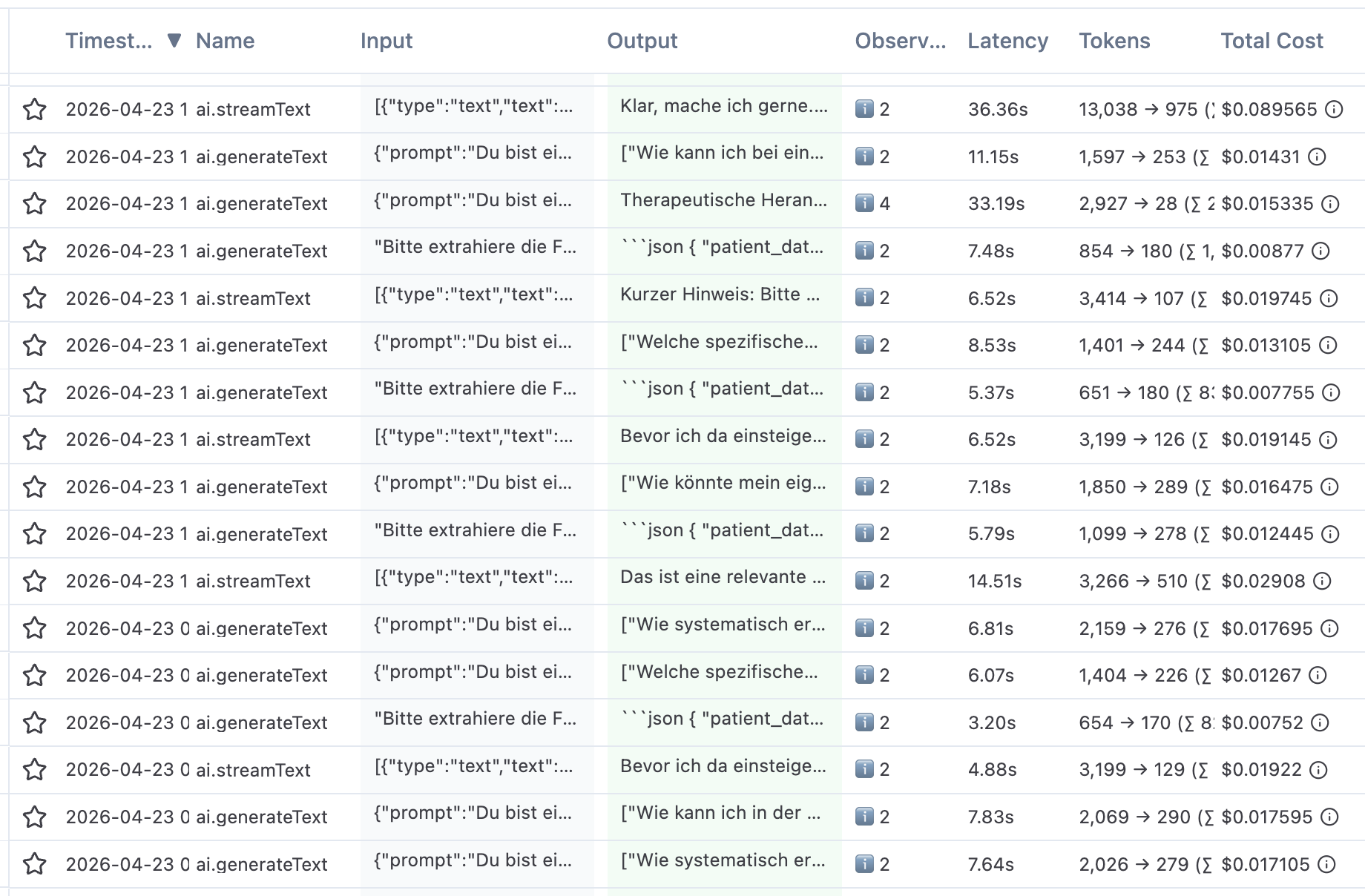
Beispiel für Traces vom ganzheit-app.com Staging System
Ich persönlich habe gute Erfahrungen mit LangFuse gemacht, das ich aktuell in zwei Projekten produktiv einsetze. Es ist Open Source, lässt sich schnell einbinden und bringt alles mit, was man in der frühen Phase braucht: Prompt-Versionierung, Traces, Kostentracking pro Aufruf, Annotation von einzelnen Antworten. Alternativen wie Braintrust oder LangSmith sollen ebenfalls gut sein – ich habe damit selbst aber nicht praktisch gearbeitet und kann daher keinen direkten Vergleich anstellen. Wichtiger als die konkrete Tool-Wahl ist, dass Ihr überhaupt eines einsetzt. Welches – das könnt Ihr getrost in Engineering-Hand legen oder anhand von ein paar Probetagen entscheiden.
Warum nur Prompt Management? Wo bleiben RAG und Fine-Tuning?
An dieser Stelle erwartet Ihr vielleicht ein Kapitel über Retrieval Augmented Generation (RAG) und Fine-Tuning. Schließlich sind das die zwei Buzzwords, die in jeder zweiten LinkedIn-Diskussion über AI-Anwendungen auftauchen. Mein Hot Take: Beides braucht Ihr in Stufe 2 mit hoher Wahrscheinlichkeit nicht – und Ihr solltet Euch auch nicht damit befassen, solange Ihr nicht aus guten Gründen ganz genau wisst, warum ihr es doch braucht.
Beginnen wir mit RAG. Die Idee dahinter ist, dass man relevante Dokumente oder Datenfragmente aus einer Vektor-Datenbank holt und sie dem LLM als zusätzlichen Kontext mitgibt. Das war vor zwei Jahren oft notwendig, weil die Kontextfenster der damaligen Modelle klein waren und man die Inhalte einfach nicht reinbekommen hat. Heute sieht die Welt anders aus. Die aktuellen Flagship-Modelle haben Kontextfenster von einer Million Tokens oder mehr – das sind grob ein paar Tausend Seiten Text. In den allermeisten Fällen, in denen Ihr in Stufe 2 stehen werdet, passen Eure relevanten Dokumente einfach komplett in den Kontext. Damit ist die ganze Komplexität von Embeddings, Vektor-Stores und Retrieval-Pipelines für den Anfang schlicht unnötig.
Eine Ausnahme gibt es: Wenn Ihr Real-Time-Daten braucht, die nicht einmalig in den Kontext geladen werden können – etwa permanent aktualisierte Produktinformationen, Verfügbarkeiten von Hotelzimmern, ein wachsender Knowledge-Base-Bestand oder personalisierte Daten aus einer großen Nutzerbasis – dann führt an einer Retrieval-Lösung kein Weg vorbei. Aber das ist eine bewusste Entscheidung, die aus einer konkreten Anforderung folgt, nicht eine Default-Wahl zu Beginn.
Beim Fine-Tuning ist die Lage noch klarer. Die Idee, ein Modell auf eigenen Daten nachzutrainieren, hat in den frühen Tagen der LLMs eine Rolle gespielt, weil die Basismodelle in vielen Domänen einfach nicht gut genug waren. Aber die heutigen Flagship-Modelle sind so gut, dass Ihr für die ersten Schritte definitiv kein eigenes Training braucht. Die Kombination aus durchdachten Prompts, gutem Kontext und aufmerksamer Iteration reicht in 99% der Fälle aus, um eine MVP-Anwendung zu bauen. Fine-Tuning ist teuer, langsam und macht Euch von Modell-Generationen abhängig – wenn das nächste Modell rauskommt, dürft Ihr nachtrainieren. Spart Euch das, solange Ihr nicht einen sehr spezifischen und sehr gut begründeten Grund habt, der dafür spricht.
Die nüchterne Wahrheit: In Stufe 2 reicht das, was ich gerade beschrieben habe. Saubere Prompts, ein Tracing-Tool, einfache Kontext-Injection für die relevanten Dokumente. Alles weitere ist Premature Optimization.
Cost Monitoring – warum die Kostenrechnung anders aussieht als bei klassischem SaaS
Ein Punkt, den ich am Anfang von AI-Projekten regelmäßig sehe: Die Kosten werden unterschätzt. Bei einer klassischen Web-Anwendung sind die Compute-Kosten in der Regel so niedrig, dass man sie als Produktmensch fast ignorieren kann. Server kosten ein paar Euro pro Monat, Datenbanken sind Cents pro Gigabyte, und ein einzelner Request kostet praktisch nichts. Bei Generative AI sieht das anders aus. Jeder einzelne LLM-Aufruf kostet Geld – und zwar nicht wenig.
Lasst mich das an einem persönlichen Beispiel illustrieren. In einem meiner Projekte habe ich vor einigen Wochen eine intensive Testsession gemacht. Ich habe alleine am Rechner gesessen, verschiedene Prompts iteriert, Konversationen durchgespielt und Edge Cases ausprobiert. Klassische MVP-Arbeit eben. Am Ende der Session habe ich in der LangFuse-Übersicht nachgeschaut, was das gekostet hat: 127 Dollar. Innerhalb von ein paar Stunden. Alleine. Für reine Test-Calls.
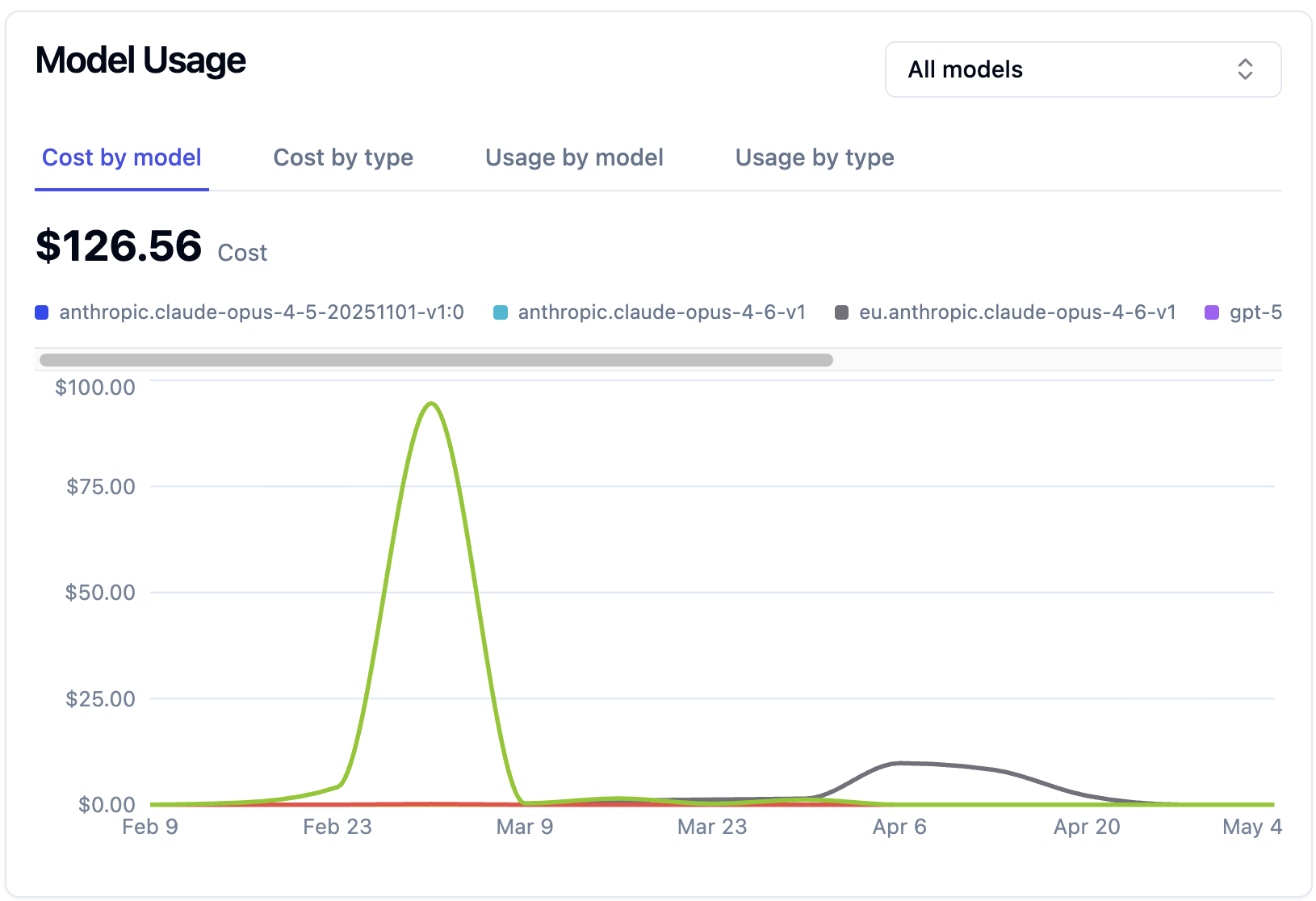
Wenn Ihr das auf eine Produktivumgebung mit echten NutzerInnen hochrechnet, wird schnell klar, was das bedeutet. Eine Anwendung mit tausend täglich aktiven NutzerInnen kann in der Infrastruktur leicht 500 bis 5.000 Euro pro Monat kosten – und das ohne Engineering-Aufwand, ohne Marketing, ohne sonstige Fixkosten. Compute ist bei LLM-basierten Anwendungen einfach teurer als bei klassischem SaaS, weil hinter jedem Aufruf ein riesiges Modell auf einer GPU dreht und nicht ein paar einfache Datenbankoperationen ablaufen.
Was heißt das praktisch? Behaltet die Kosten vom ersten Tag an im Blick. Die meisten LLM-Engineering-Plattformen, auch LangFuse, zeigen Euch pro Trace, pro Modell und pro Tag, was die Inferenz gekostet hat. Schaut da regelmäßig drauf. Lernt ein Gefühl dafür, was ein einzelner Aufruf ungefähr kostet und wie sich Prompt-Länge, Modellwahl und Output-Länge auf die Kosten auswirken. Das ist für die spätere Frage des Business Cases zentral. Eine KI, die Euer Problem zwar löst, aber zu Kosten, die jeden möglichen Preis übersteigen, ist eben keine Lösung.
Drei Hebel, die in der Praxis am meisten ausmachen: Erstens die Modellwahl. Das Flagship-Modell, das Euch in Stufe 1 überzeugt hat, ist meistens nicht das Modell, das Ihr für jeden Call in Produktion braucht. Einfache Klassifizierungen, Formatierungen oder Routing-Entscheidungen laufen oft genauso gut auf einem deutlich günstigeren Modell – Haiku statt Opus, Mini statt Pro. Probiert das früh aus. Zweitens die Output-Länge. Ein Modell, das einen JSON mit drei Feldern zurückgibt, kostet einen Bruchteil dessen, was eine ausführliche Erklärung kostet. Wenn Ihr keinen Fließtext braucht, schränkt das Format hart ein. Drittens Prompt Caching, das alle großen Anbieter inzwischen unterstützen: Wenn Euer System-Prompt und Kontext zwischen Calls identisch sind – was im MVP fast immer der Fall ist – bezahlt Ihr für den wiederholten Teil nur einen Bruchteil. Das einzuschalten ist meist eine Frage von Minuten und kann die Inferenzkosten halbieren.
Datenschutz – API-Calls oder selbstgehostetes LLM?
Das Stichwort Kosten leitet direkt zum nächsten Thema über: Datenschutz und Hosting. Je nachdem, was Eure Anwendung tut und mit welchen Daten sie umgeht, müsst Ihr Euch früh die Frage stellen, ob ein direkter API-Call an Anthropic, OpenAI oder Google in Eurem Setup überhaupt tragbar ist. Bei einem internen Tool zur Datenanalyse mag das kein Problem sein. Bei einer Anwendung mit medizinischen Daten, Mandantengeheimnis oder anderen besonders schützenswerten Inhalten sieht das schnell anders aus.
Ein Punkt, der in Rechtsabteilungs-Diskussionen oft hängen bleibt und den Ihr direkt entkräften könnt: Über die API-Zugänge der großen Anbieter werden Eure Inputs und Outputs standardmäßig nicht zum Training der Modelle verwendet. Das gilt sowohl für die direkten APIs von Anthropic und OpenAI als auch für die Wege über AWS Bedrock, Azure AI Foundry und Vertex AI – in allen vier Fällen ist Training-by-Default ausgeschaltet, ohne dass Ihr opt-out wählen müsst. Das ist ein wichtiger Unterschied zu den Consumer-Produkten wie Claude oder ChatGPT, bei denen das Default-Verhalten seit den Policy-Änderungen im Spätsommer 2025 anders aussieht. Wenn Euch also jemand in der Diskussion vorhält, dass Eure Daten "in der KI verschwinden" – das ist im API-Kontext schlicht falsch.
Eine weitere gute Nachricht: Selbst wenn Ihr aus Datenschutzgründen die LLMs auch mit deaktiviertem Training nicht direkt per API anrufen könnt, gibt es saubere Lösungen, die ohne große Eigenentwicklung auskommen. AWS Bedrock, Azure AI Foundry und Google Enterprise Agent Platform bieten genau diese großen Modelle, aber gehostet innerhalb der jeweiligen Cloud-Boundary, mit klaren Data-Processing-Agreements und der Möglichkeit, die Verarbeitung auf bestimmte Regionen einzugrenzen. Wenn Ihr ohnehin schon auf einer dieser Plattformen seid, ist das in der Regel der pragmatischste Weg.
Kostenmäßig fällt diese Option meist etwas teurer aus als der direkte Aufruf, aber deutlich weniger, als man häufig hört. Die Per-Token-Preise bei den großen Hyperscalern entsprechen für Claude-Modelle inzwischen weitgehend denen der direkten Anthropic-API. Der spürbare Aufpreis von rund 10% kommt erst dann ins Spiel, wenn Ihr region-gepinnte Endpoints nutzt, also genau die Konfiguration, die Ihr aus Datenschutzgründen typischerweise wählen würdet. Zehn Prozent Aufschlag sind verschmerzbar dafür, dass Eure Daten die Cloud-Boundary nicht verlassen.
Ein letzter Punkt, der mir an dieser Stelle wichtig ist, weil er sich hartnäckig als Mythos hält: Datenschutz mit einem selbstgehosteten oder Cloud-gehosteten LLM ist nicht grundsätzlich anders als Datenschutz in klassischem SaaS. Ich höre immer wieder Stimmen, die behaupten, KI sei eine fundamental neue Risikokategorie, die ganz eigene rechtliche Bewertungen brauche. Das ist Quatsch. Am Ende haben wir es mit ausgefeilten statistischen Modellen zu tun, die auf Computern laufen, dieselben Daten verarbeiten wie jede andere Software und denselben Datenschutzbestimmungen unterliegen. Wenn Ihr eine klassische Web-Anwendung DSGVO-konform hosten könnt, könnt Ihr auch eine LLM-Anwendung DSGVO-konform hosten. Nicht mehr und nicht weniger. (Kleiner Hinweis: Ihr müsst natürlich nicht nur bei der Arbeit des LLMs, sondern auch beim Tracing berücksichtigen, wo die Daten verarbeitet werden – auch das ist aber einfach lösbar.)
Lasst Euch von dieser Mystifizierung nicht verunsichern. Ihr braucht denselben Sachverstand wie sonst auch – nicht mehr.

Was bringt dieser Tech Stack für Generative-AI-Anwendungen?
Wenn Ihr Stufe 2 sauber durchgezogen habt, sieht Euer Setup ungefähr so aus: Ihr habt eine erste Version Eurer Anwendung, die einen echten Use Case abbildet. Eure Prompts liegen versioniert in einem Prompt-Management-Tool und nicht im Code. Jeder einzelne Aufruf wird als Trace erfasst, sodass Ihr nachvollziehen könnt, was rein- und was rausgegangen ist. Ihr habt einen Blick auf die Kosten und wisst ungefähr, was Euch ein typischer Nutzer-Aufruf kostet. Und Ihr habt eine Hosting-Entscheidung getroffen, die zu Eurem Datenschutzbedarf passt.
Bewusst nicht dabei: Vektor-Datenbanken, Fine-Tuning, eigene Modelle, ein komplexes Agent-Framework, Multi-Step-Reasoning-Pipelines mit fünf verschiedenen LLMs im Verbund. All das sind Werkzeuge in der LLM-Toolbox, aber sie gehören in spätere Stufen, wenn klar ist, dass die einfachere Lösung das Problem nicht mehr trägt. In Stufe 2 ist das Ziel nicht Eleganz, sondern Lernfähigkeit. Ihr wollt etwas in der Hand haben, das Ihr ernsthaft mit Menschen testen könnt, und das Ihr schnell anpassen könnt, wenn Ihr im Test seht, dass etwas nicht passt.
Genau dahin geht es als Nächstes. In Stufe 3 und 4 – dem internen und externen MVP Testlauf – nehmen wir die Anwendung in die Hand, übergeben sie erst freundlichen Nutzern und dann Fremden, um zu sehen, was passiert. Ihr werdet feststellen, dass Eure NutzerInnen Dinge mit Eurem Produkt machen, die Ihr nie erwartet hättet, und dass die Liste der Edge Cases plötzlich deutlich länger wird als gedacht. Das ist nicht schlimm – das ist genau der Punkt. Wir bauen keine perfekte Software, wir bauen Software, die am Kontakt mit der Realität besser wird.
Der Artikel zu Stufe 3 folgt zeitnah, sobald ich Zeit habe. Bis dahin: Setzt Euer Tracing auf, schreibt Eure ersten Prompts ordentlich versioniert und schaut Euch die Kostenseite an. Das ist die Grundlage für alles, was folgt. Und wenn es schon weitergehen soll, lohnt ein Blick auf den Übersichtsartikel.